You know how there are websites where you don't have to think of a new username and password when you register, and you can just log in with Facebook or Google instead? That's called SSO - Single Sign On, and there's a huge trend towards adopting this approach all over the web.
The arguments in favor seem strong:
- It's easy. Users don't want to generate a new set of credentials. SSO will thus cause less users to drop out before registering.
- It's secure. The more credentials a user has to keep track off, the less secure his online world is going to be, since he'll likely choose the same easy-to-remember passwords over and over.
- It's faster. One less thing to do to register. Just click on the big, familiar Facebook button, then up comes a pop-up from Facebook asking for permission, and you're done.
- It's ubiquitous. Basically everybody already has a Facebook/Gmail account.
- It's less headache. You're not storing user credentials, so the townspeople won't come after you with pitchforks when you get hacked.
- It's easy to implement. In fact, there ain't much to implement, since it's been done a thousand times before and is offered as a library or a service.
So, easiest decision ever, right? Our new website shall be a beacon of progress, relying only on SSO for authentication.
Or
is it?
Pam, pam, paaaaaam!
One of the popular proponents of SSO is
Stack Overflow. From the day it launched, Stack Overflow never offered a traditional log in option - only SSO. Here's what their log-in screen looks like:
So, which account
did we sign-up with to Stack Overflow? Was it the Google or Facebook option?
What happens if I choose the wrong one? Would a new account be created? Are these the sort of questions you need your users to be asking themselves constantly?
In short - SSO is not
that easy, at least when there's more than one SSO option to choose from.
More choice isn't always good. Too much of it can lead to inaction - users turning away.
There isn't always that much choice. Here's
meetup.com's log in page:
Granted, I still need to remember if I registered with my own credentials or with Facebook, but I guess that's a bit easier to remember.
At least SSO is still faster, right? You don't have to type anything or try every one of your different passwords till you get the right one. But then again, doesn't the browser already do that? Every browser now offers to remember your log in details for you, and some even go ahead and fill out the log in form for you automatically. Browsers have become password managers, and pretty good ones at that. With a password manager working for you, logging in becomes just one click. That's actually faster than with SSO. With SSO, first you have to click on your SSO provider (click #1) and then, depending on whether or not you're already logged in to Facebook or whatever you have to also wait for their pop-up (so slow...) and either click inside it to confirm, or (worse) actually do the whole log in thing with Facebook.
So, traditional log in: 1 click.
SSO: 1 click + a whole lot of waiting for popups + potentially an additional log-in
But wait, there's more! If you really care about security and speed, you're likely using a full fledged password manager, like
LastPass. LastPass doesn't just keep track of your passwords
very securely, it also generates them for you - nice, long, random ones. But, most importantly, LastPass works very hard to make sure it knows how to auto-fill every bloody log in form on every bloody web site. It's not a hit-or-miss feature, like the ones inside browsers. And, if you choose,
it will automatically click on the log in button for you. So if you're using LastPass you can actually skip the entire log-in process entirely.
Zero clicks.
To recap: SSO - 1 click at the very minimum; Traditional log-in: 0 clicks.
SSO is actually much, much slower than traditional credentials.
And SSO isn't really more secure than using a good password manager. In either case once your main password (for Facebook/LastPass) is compromised, hackers can log in to any of your SSO accounts. Granted, more people use Facebook than LastPass, so SSO still has the upper hand in terms of ubiquity, but, with time, I believe we'll see the equivalent of LastPass built into every browser.
The last point is about implementation. Here, traditional passwords are easiest, no doubt. They're built into any decent web framework or CMS, so there's really nothing to implement. I've done both and getting SSO to work is pretty easy, but certainly not easier than traditional authentication. And as long as you're not rolling your own, you're likely using a very well tested and secure implementation, which doesn't actually store passwords - only
salted hashes thereof - so hacking your site won't give hackers access to your users' other accounts.
All of this is why
Gigantt has been using the traditional log in method until now, and we're not likely to change it soon. Down the line - maybe, if it actually helps us reach more users. But we probably won't offer more than one SSO option and we'll almost certainly always keep the traditional log-in option around.

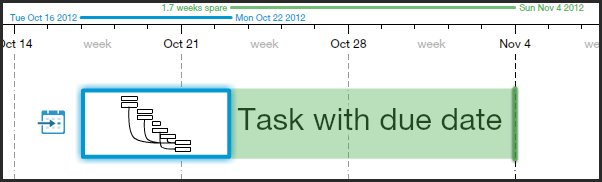
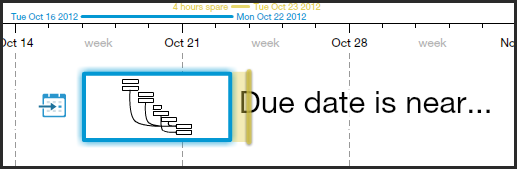
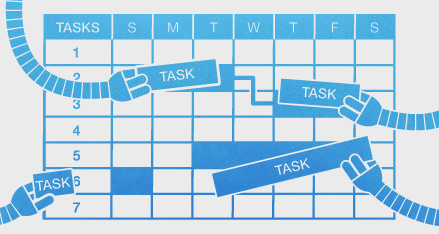 Naturally, this affects Gigantt's automatic task scheduling. With this new information the schedules you're going to get will be a lot more realistic.
Naturally, this affects Gigantt's automatic task scheduling. With this new information the schedules you're going to get will be a lot more realistic. 






























{kind=link}